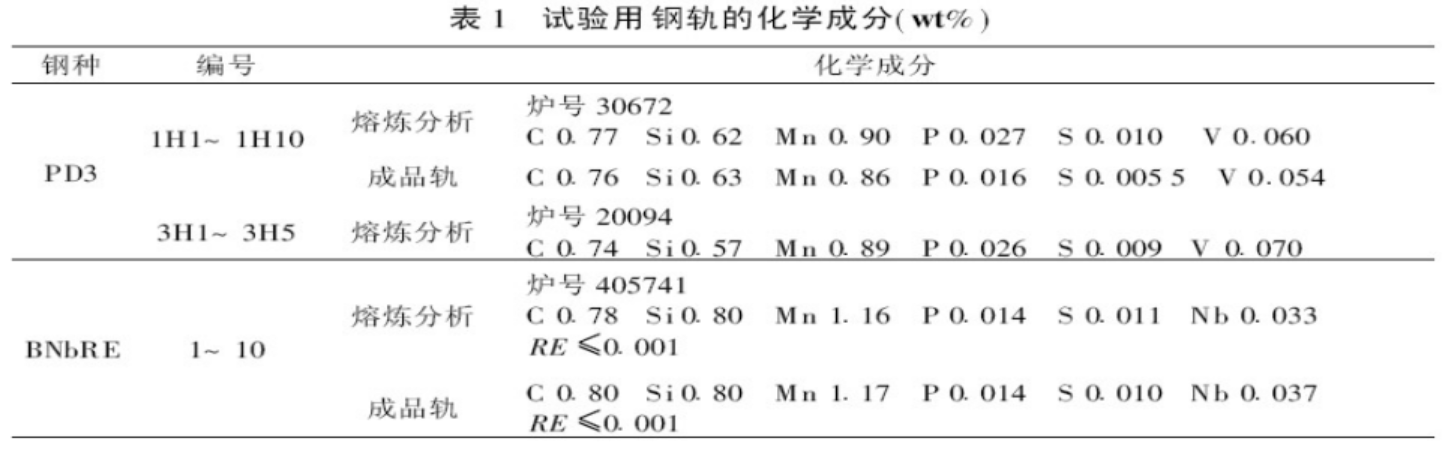
一、层序遍历
广度优先搜索:使用队列,先进先出
模板:
1、定义返回的result和用于辅助的队列
2、队列初始化:
root非空时进队
3、遍历整个队列:大循环while(!que.empty())
记录每层的size以及装每层结果的变量(记得每层循环结束后保存结果的值)
4、遍历每层:小循环for或while(size--)
出1进2:先记录当前即将出队的node
node出队,如果孩子节点非空即进队
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> result;
//借助队列来实现
queue<TreeNode*>que;//(先进先出,层序遍历)(保存节点指针,孩子信息才不丢失)
if(root) //先弹进root
que.push(root);
while(!que.empty()){//队列不为空时,都要遍历;没有继续加入的,则说明快要遍历完了
int size=que.size(); //保存当前层的大小
vector<int> vec;//vec记录每层的节点元素,在循环内定义,不用每次清空
//将总遍历切割成一层一层的
while(size--){
//对一层元素进行操作:出一个根节点(要先记录val),则进两个它的孩子节点(如果有)
TreeNode*node=que.front();
vec.push_back(node->val);
que.pop();
if(node->left)
que.push(node->left);
if(node->right)
que.push(node->right);
}
result.push_back(vec);
}
return result;
}变式:求层平均值

vector<double> averageOfLevels(TreeNode* root) {
vector<double> result;
queue<TreeNode*> que;
if(root!=NULL)
que.push(root);
while(!que.empty()){
int size=que.size();//当前层元素个数
double sum=0;
for(int i=0;i<size;i++){
TreeNode* node=que.front(); //先保存
sum+=node->val;
que.pop();//再弹出
if(node->left)//最后进两个
que.push(node->left);
if(node->right)
que.push(node->right);
}
result.push_back(sum/size);
}
return result;
}注意:最后要用到sum/size;所以不能用while(size--),因为size会改变,而要用for循环
同理,每层循环要记录size,就是因为que.size()也会改变
二、深度遍历(前中后序,递归)
深度优先搜索:使用栈,先进后出
模板:
前序:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
vec.push_back(cur->val); // 根
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
}中序:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
traversal(cur->left, vec); // 左
vec.push_back(cur->val); // 根
traversal(cur->right, vec); // 右
}后序:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
vec.push_back(cur->val); // 根
}三、对比
1、获取最大深度

深度优先(前序):
int getdepth(TreeNode* node) {
if (node == NULL) return 0;
int leftdepth = getdepth(node->left); // 左
int rightdepth = getdepth(node->right); // 右
int depth = 1 + max(leftdepth, rightdepth); // 中
return depth;
}广度优先:
int maxDepth(TreeNode* root) {
//1、定义结果变量和辅助队列
int depth=0;
queue<TreeNode*> que;
//2、队列初始化
if(root)
que.push(root);
//3、大循环并记录每层的size
while(!que.empty()){
int size=que.size();
//4、小循环:遍历一层,存1出1进2
while(size--){
TreeNode*node=que.front();
que.pop();
if(node->left)
que.push(node->left);
if(node->right)
que.push(node->right);
}
depth++;
}
return depth;
}2、获取最小深度
深度优先(前序):
int minDepth(TreeNode* root) {
if(root==NULL)
return 0;
int lh=minDepth(root->left);
int rh=minDepth(root->right);
if(!root->left&&root->right)
return 1+rh;
if(root->left&&!root->right)
return 1+lh;
return 1+min(lh,rh);
}考虑仅有一个孩子节点时,返回的应是1+子树的最小深度
广度优先:
int minDepth(TreeNode* root) {
//1、定义结果变量和辅助队列
int depth=0;
queue<TreeNode*> que;
//2、队列初始化
if(root)
que.push(root);
//3、大循环并记录每层的size
while(!que.empty()){
int size=que.size();
//4、小循环:遍历一层,存1出1进2
while(size--){
TreeNode*node=que.front();
que.pop();
if(node->left)
que.push(node->left);
if(node->right)
que.push(node->right);
//如果遇到叶子节点了,说明可以完成最小深度计算了
if(!node->left&&!node->right)
return depth+1;//注意是+1(逻辑上要遍历完一层才+1,这里提前结束就提前加)
}
depth++;
}
return depth;
}考虑遇到叶子节点时,就可以返回最小深度了